Hör dir an, wie wir eine Gesangsspur von der einfachen Aufnahme zu einem Track in professioneller Qualität bringen – und dir den Prozess dazu Schritt für Schritt erklären.
Von Pop bis Rock, von RnB bis Rap – Gesang ist das Herzstück vieler moderner Musikstile. Für Zuhörende muss der Gesang deutlich hörbar sein, damit sie den Text verstehen können. In vielen Genres stehen die Vocals im Mittelpunkt, so dass es ein echter Abtörner sein kann, wenn sie im Gesamtkontext untergehen. Umgekehrt sollte der Gesang aber auch nicht zu sehr herausstechen. Als Produzent oder Tontechniker ist es also deine Aufgabe, dafür zu sorgen, dass der Gesang eines Songs klar, präsent und im Verhältnis zu den anderen Elementen des Tracks ausgewogen ist.
In diesem Artikel werden wir sonible-Plugins und eine Reihe von fortgeschrittenen Vocal-Mixing-Techniken verwenden, um einen professionellen Vocal-Mix des folgenden Demo-Tracks zu erstellen. Wie du anhand des Audiobeispiels hören kannst, klingt der Gesangspart des Demos leblos, dünn und uninspiriert. Zudem wirkt es so, als würde der Gesang losgelöst vom Rest des Mixes stattfinden und es ist schwer, den Text richtig zu verstehen.
Zuerst kommt smart:deess zum Einsatz, um einige Plosive und Zischlaute in der Gesangsaufnahme zu beseitigen. Während der Gesang in der Strophe recht dumpf klingt, enthält der Refrain einige Zischlaute bei den ‘S’-Klängen. Zudem sind einige subtile Plosive wahrnehmbar, die aber in diesem Fall weniger problematisch sind.
Sobald wir smart:deess auf den Vocal-Kanal geladen haben, fordert uns das Plugin auf, das Audiomaterial analysieren zu lassen.
Wir spielen den problematischen Bereich der Stimme in Schleife ab und klicken auf ‘Analyze Voice’. smart:deess analysiert dabei das Audiomaterial, um Plosive oder Zischlaute in der Stimme zu identifizieren.
Wenn smart:deess mit dem Analysieren der Stimme fertig ist, zeigt das Spektogramm in der oberen Hälfte der Benutzeroberfläche die Zischlaute in grün und die Plosive in blau an. In der unteren Hälfte der Benutzeroberfläche wird über die Wellenformansicht die vom Plugin vorgenommene Gain-Reduction sichtbar gemacht.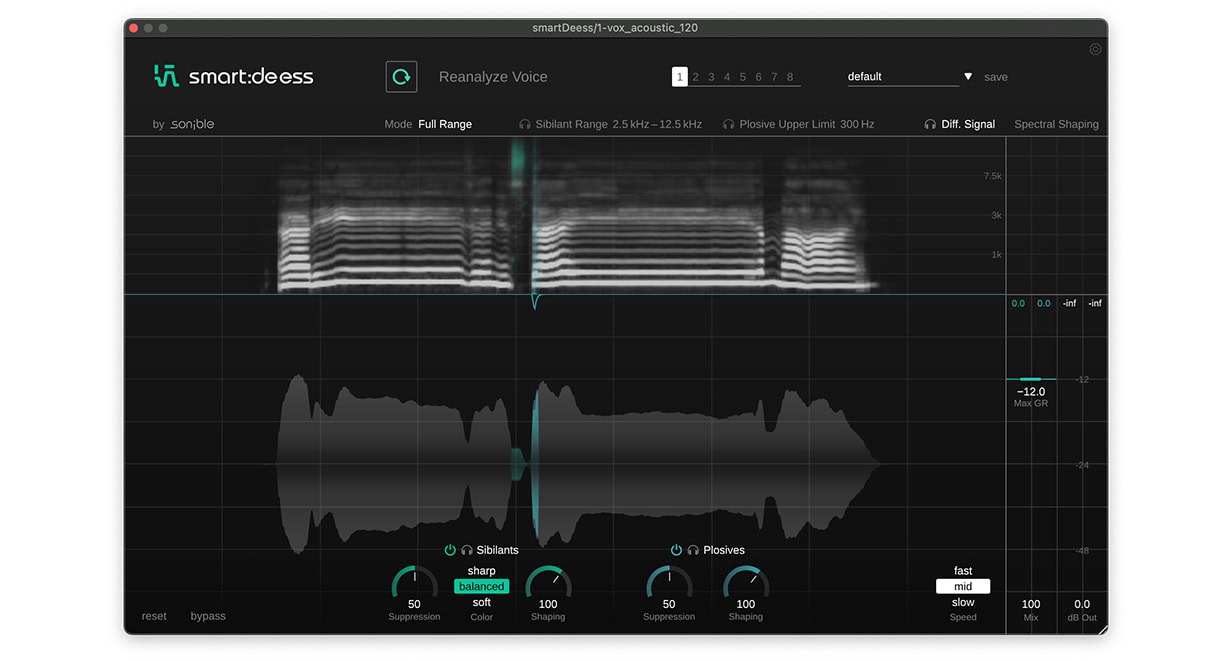
Die meisten Default-Settings bewirken einen subtilen De-Essing-Effekt, wobei Charakter und Klang des trockenen Gesangs weitgehend erhalten bleiben. Da diese Vocals jedoch von vornherein relativ smooth sind, können wir den Color-Modus „sharp“ wählen, der ein präziseres De-Essing ermöglicht, bei dem mehr vom Glanz der Vocals erhalten bleibt.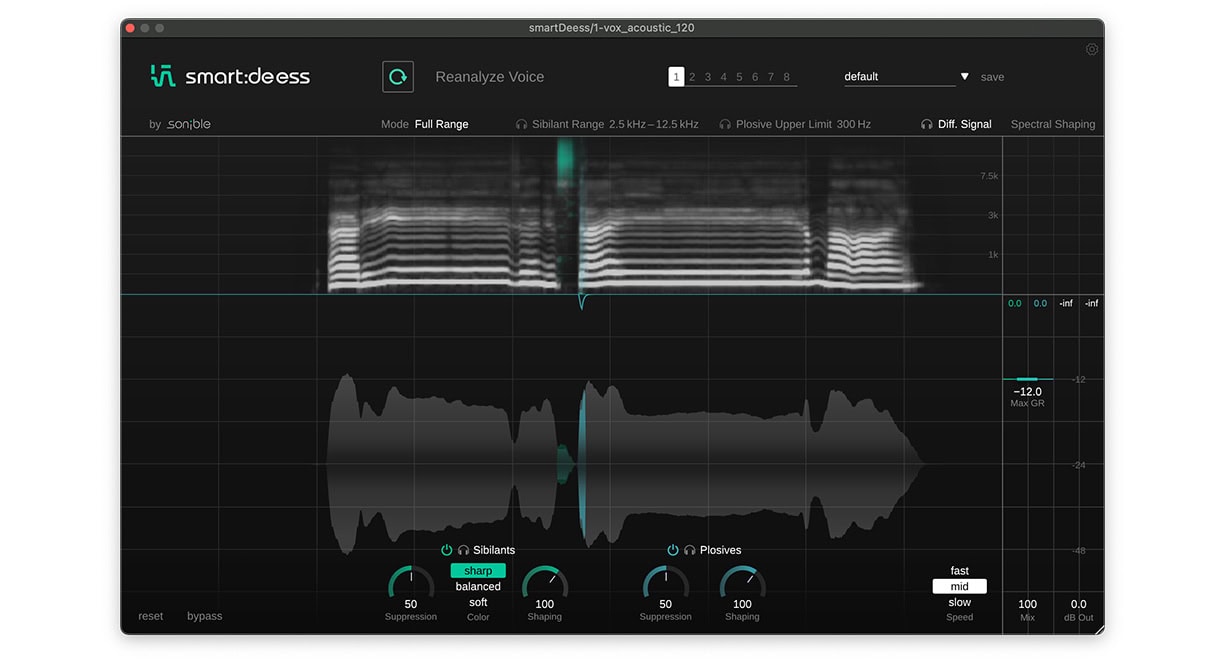
Um zu hören, wie sich smart:deess auf dein Audiomaterial auswirkt, kannst du den Diff.-Signal-Modus aktivieren. Damit lässt sich der Unterschied zwischen In- und Output-Signal abhören – auch bekannt als Delta-Signal. Auch wenn das hilfreich ist, um die angewandte Bearbeitung zu verfeinern, ist es immer am besten, die Ohren zu benutzen und sich das Audio im Kontext der gesamten Mischung anzuhören.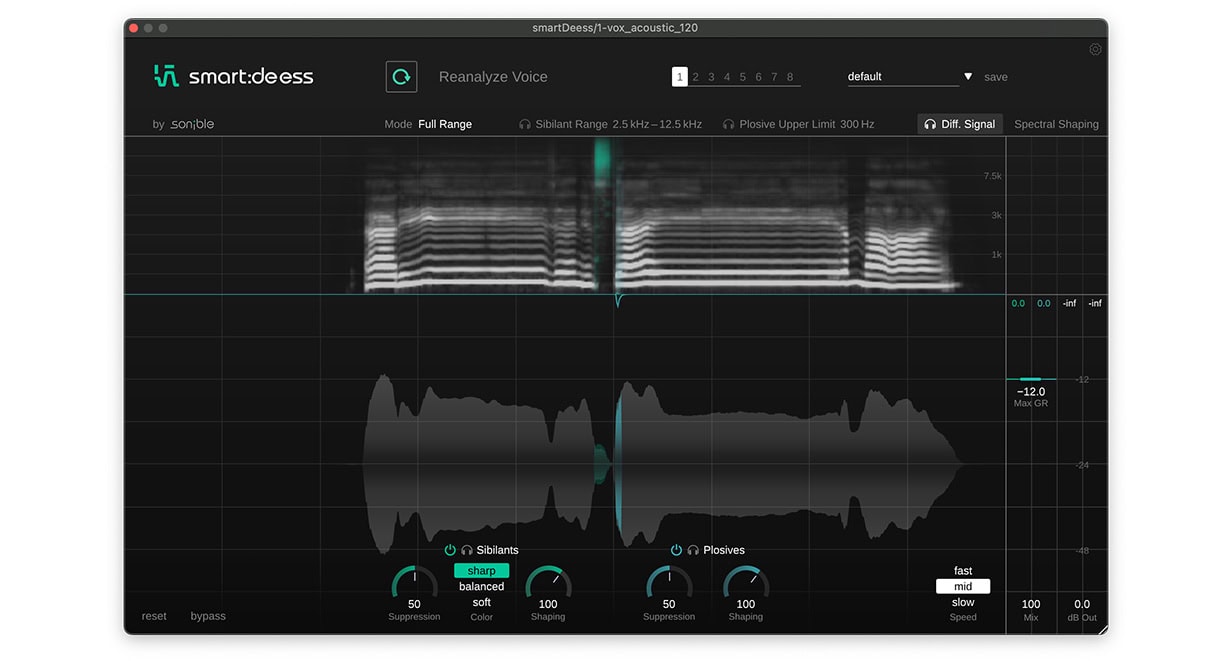
Diese Gesangsaufnahme hat keine massiven Probleme mit Plosiv- und Zischlauten, aber die Bearbeitungen, die wir als Nächstes vornehmen werden, könnten diese kleinen Probleme verschlimmern. So ist es am besten, Schwachstellen frühzeitig anzugehen, damit wir mit einem möglichst sauberen Audiosignal in den Mischprozess gehen können.

Als Nächstes werden wir die Dynamik des Gesangs auf natürliche und musikalische Weise angehen und dabei dem Audiomaterial etwas mehr ‘Body’ verleihen. Wie bei vielen Gesangsdarbietungen sind einige Liedzeilen, Wörter und Silben viel lauter als andere, wodurch sie aus dem Mix herausstechen. Dies ist in der Wellenform unten zu sehen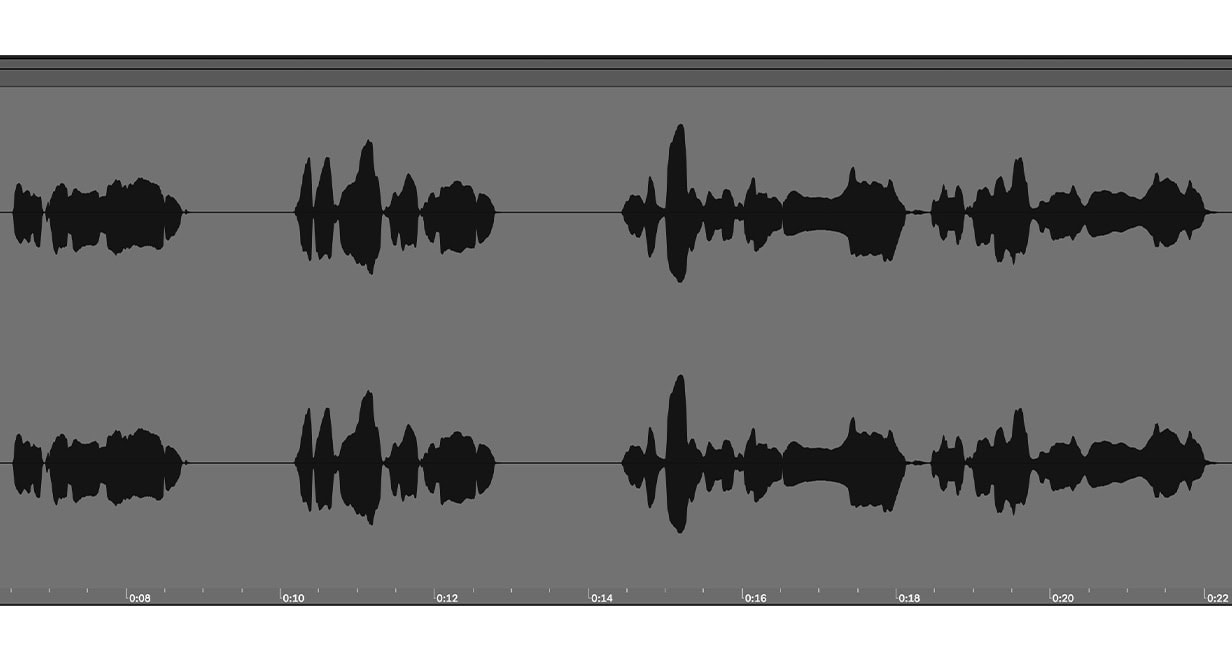 Um diese unpassenden Peaks zu kontrollieren, verwenden wir zwei Instanzen von smart:comp 2, um eine serielle Kompression durchzuführen. Lade die erste Instanz von smart:comp 2 auf deine Gesangsspur und loope den Abschnitt mit den größten Peaks. Reduziere die Ratio zwischen 4:1 und 5:1 sowie den Threshold, bis der Kompressor beginnt den Gain der lautesten Teile des Signals zu begrenzen.
Um diese unpassenden Peaks zu kontrollieren, verwenden wir zwei Instanzen von smart:comp 2, um eine serielle Kompression durchzuführen. Lade die erste Instanz von smart:comp 2 auf deine Gesangsspur und loope den Abschnitt mit den größten Peaks. Reduziere die Ratio zwischen 4:1 und 5:1 sowie den Threshold, bis der Kompressor beginnt den Gain der lautesten Teile des Signals zu begrenzen. 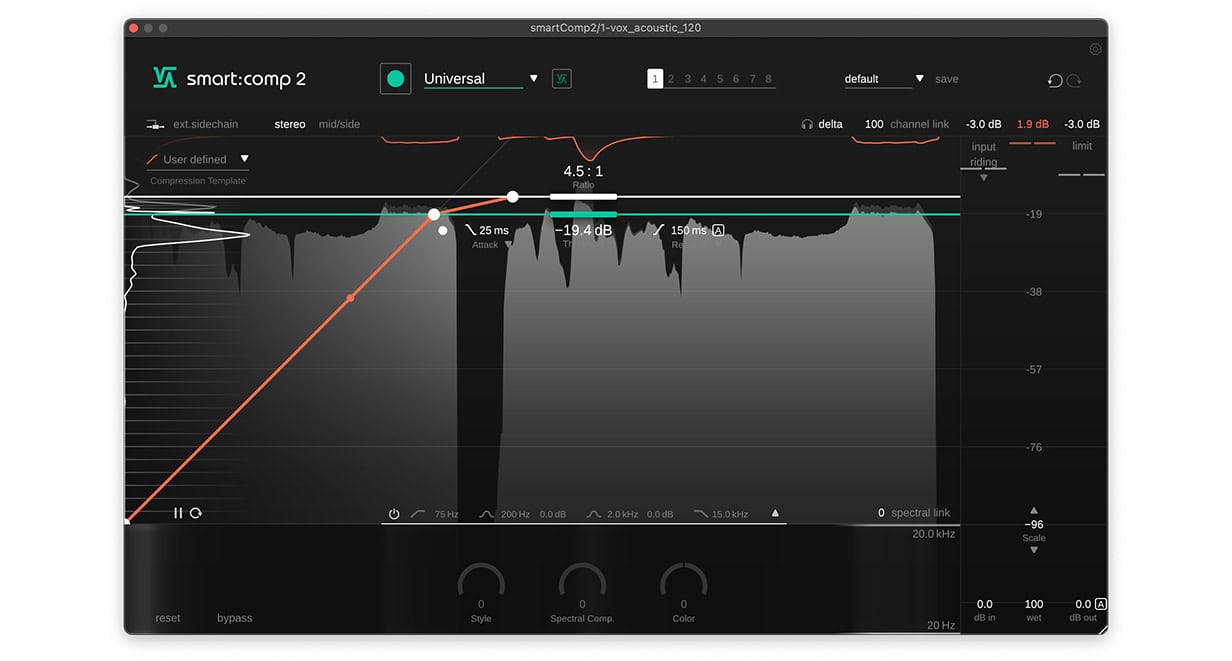
Die Aufgabe des ersten Kompressors ist es, die dynamischen Spitzen abzufangen, daher arbeiten wir mit schnellen Attack- und Release-Zeiten von 5 ms beziehungsweise 40 ms. Das ist ein guter Ausgangspunkt, jedoch solltest du immer deine Ohren nutzen und diese Werte an dein Audiomaterial anpassen.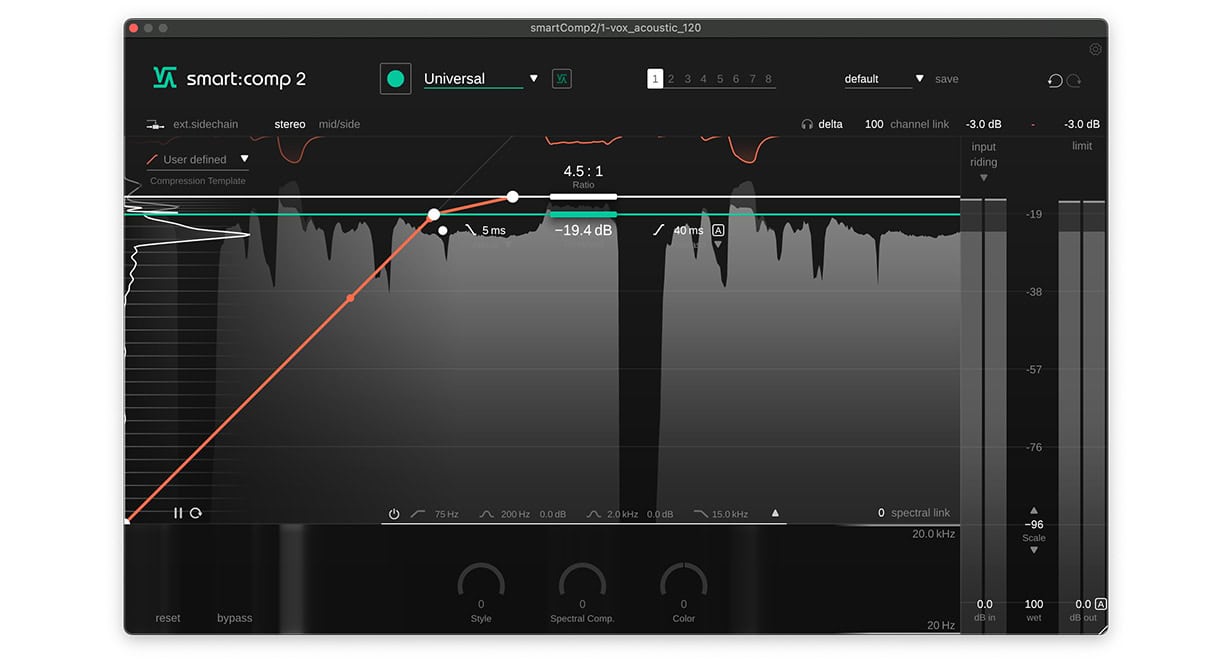
Die Aufgabe des zweiten Kompressors besteht darin, mehr generelle Gain-Reduction auf den gesamten Gesang anzuwenden. Das hilft dabei, der Stimme mehr Body und Zusammengehörigkeit zu verleihen. Auch hier nutzen wir smart:comp 2. Diesmal nutzen wir die intelligenten Funktionen des Plugins, um eine präzise und ausgewogene Dynamik des Gesangs zu erreichen. Nachdem du die zweite Instanz von smart:comp 2 auf die Gesangsspur geladen hast, wähle das entsprechende Profil aus dem Dropdown-Menü und klicke anschließend auf den Learn-Button.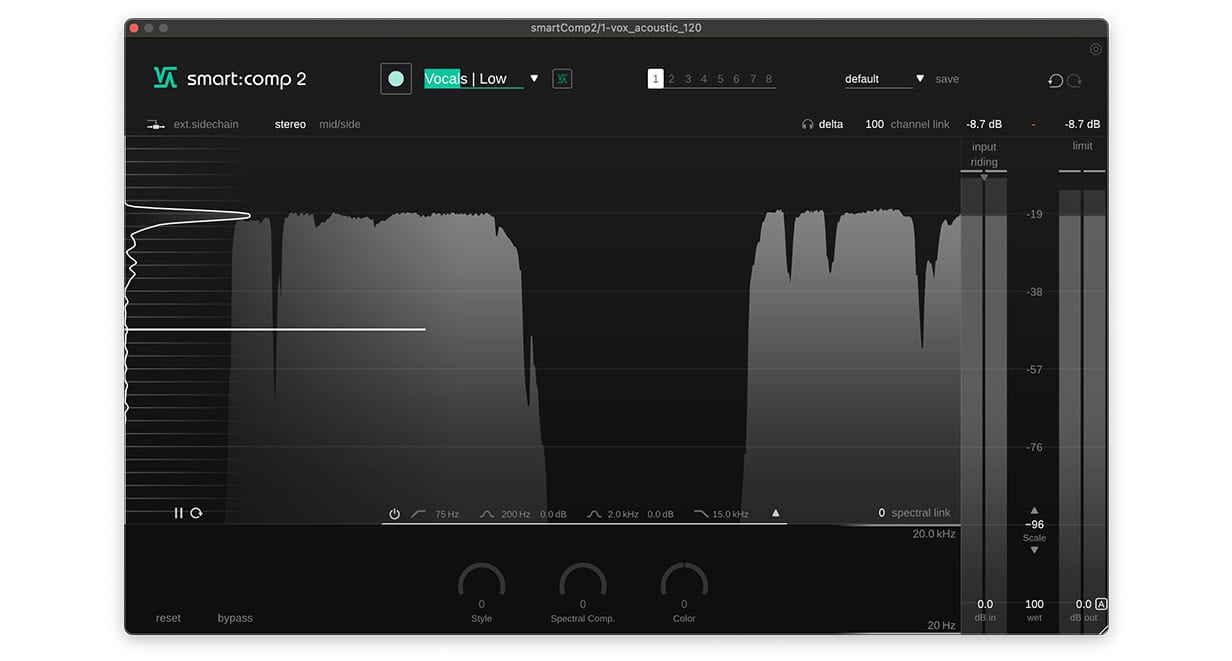
Nachdem smart:comp 2 das Signal analysiert hat, stellt er automatisch die empfohlenen Werte für Ratio, Threshold sowie Attack und Release für deine Vocals ein. Bei Bedarf kannst du für diese Parameter nach Belieben Feineinstellungen vornehmen. Du kannst auch die anderen Parameter nutzen, um den Klang und Charakter der angewendeten Kompression zu verfeinern. Beispielsweise erhalten die Vocals einen wärmeren, strafferen Charakter, wenn wir den Style-Parameter erhöhen.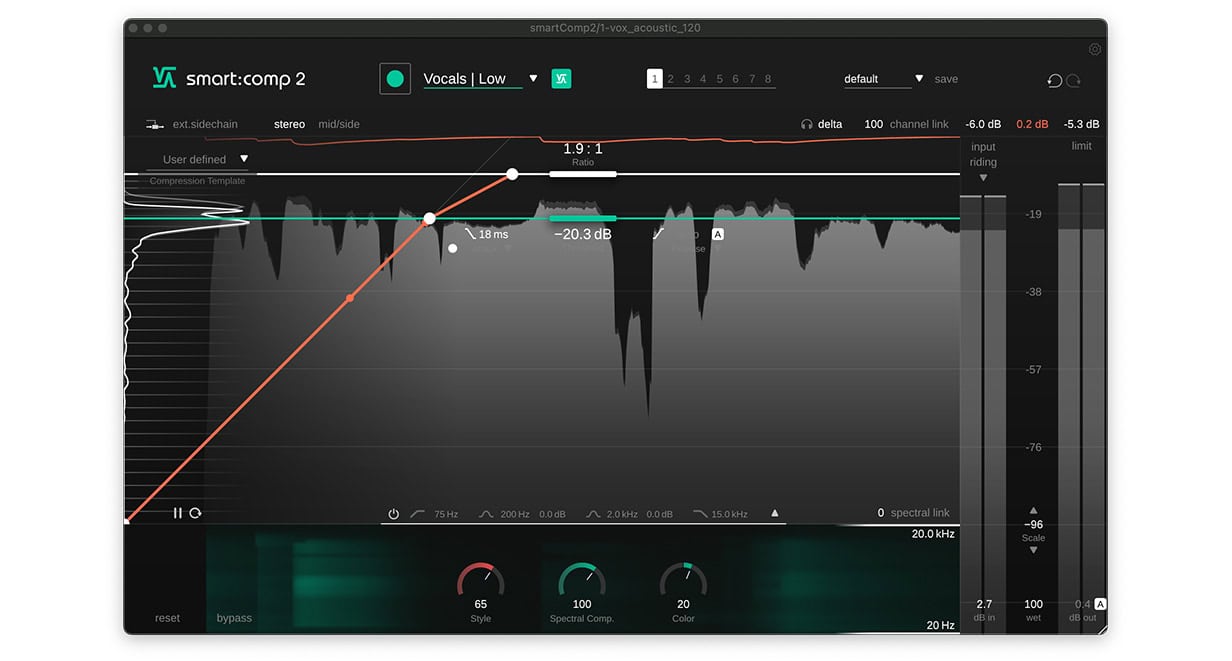
Der Klang der Originalstimme lässt sehr zu wünschen übrig. Sie klingt leicht dumpf, was es schwierig macht, den Text zu verstehen. Außerdem ist die Stimme ‘honky’ oder ‘boxy’, was für ein unangenehmes Hörerlebnis sorgt. Wir werden smart:EQ 4 verwenden, um den Klang des Gesangs zu verbessern.
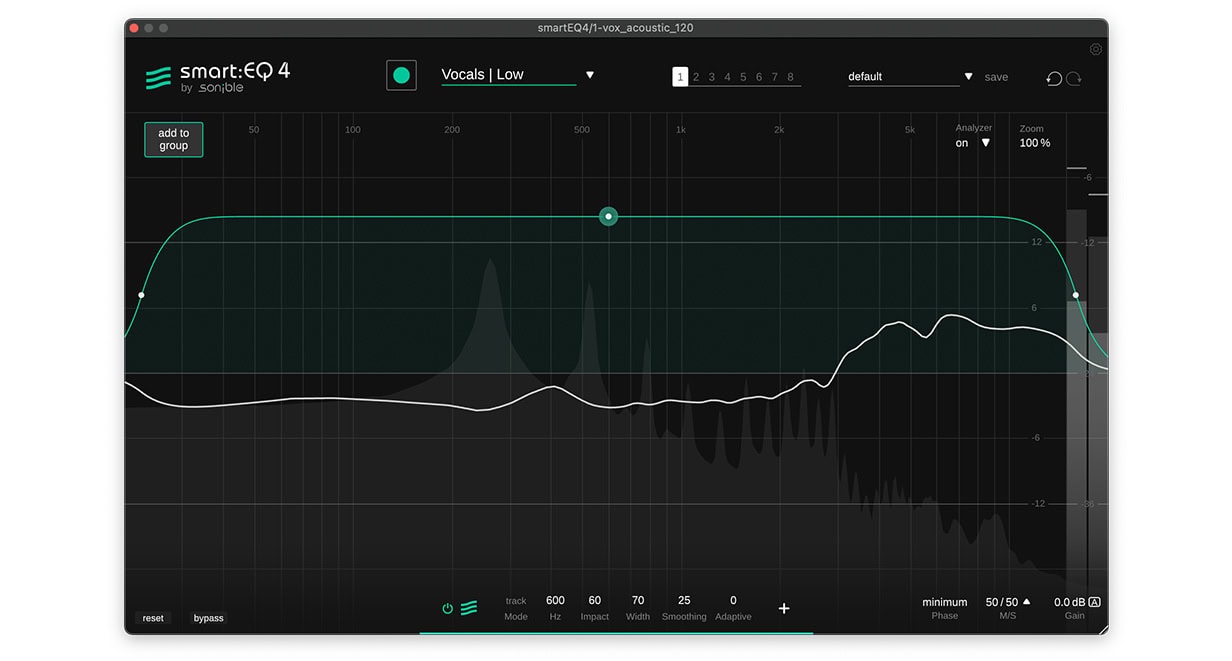
Nachdem wir smart:EQ 4 auf den Gesangskanal geladen haben, müssen wir wie bei unserem zweiten Kompressor das passende Profil auswählen. Auch hier analysiert das Plugin das Signal und wendet eine empfohlene Bearbeitung an. Du kannst sofort hören, wie sich die Stimme durch den EQ öffnet.
Im Top-End der Stimme – bei etwa 8 kHz bis 9 kHz – ist ein leichtes Brummen oder Raspeln zu hören. Dieser Frequenzbereich wurde von smart:EQ 4 akzentuiert, wir können das Problem jedoch auch manuell angehen, indem wir auf den Smart Filter im Main Display doppelklicken. Dadurch wird ein neues EQ-Band erstellt, das wie ein herkömmlicher EQ funktioniert.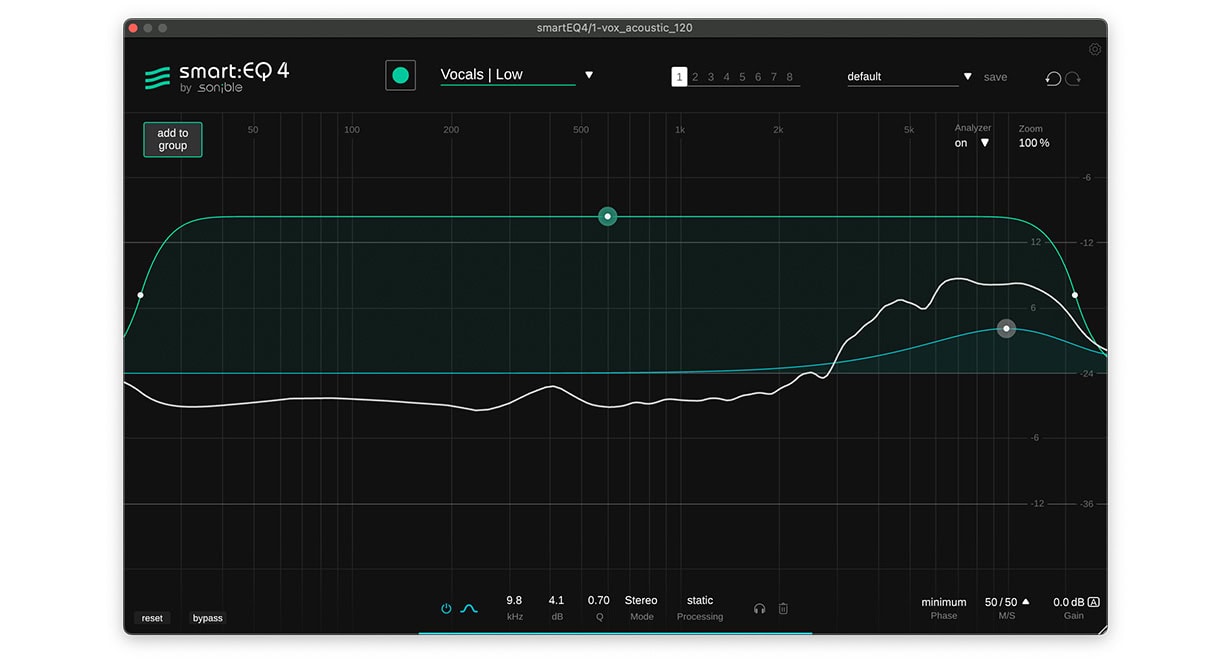
Mit einem Glockenfilter und einem niedrigen bis mittleren Q-Wert von etwa sechs haben wir einige dieser unerwünschten Frequenzen abgeschwächt. Dadurch klingt die Stimme ausgewogener und definierter. Zudem haben wir die Informationen unterhalb von 150 Hz entfernt, da sie bei dieser Stimme relativ unnötig sind und wir so mehr Raum für andere Elemente in den tiefen Frequenzbereichen wie Kick und Bass schaffen.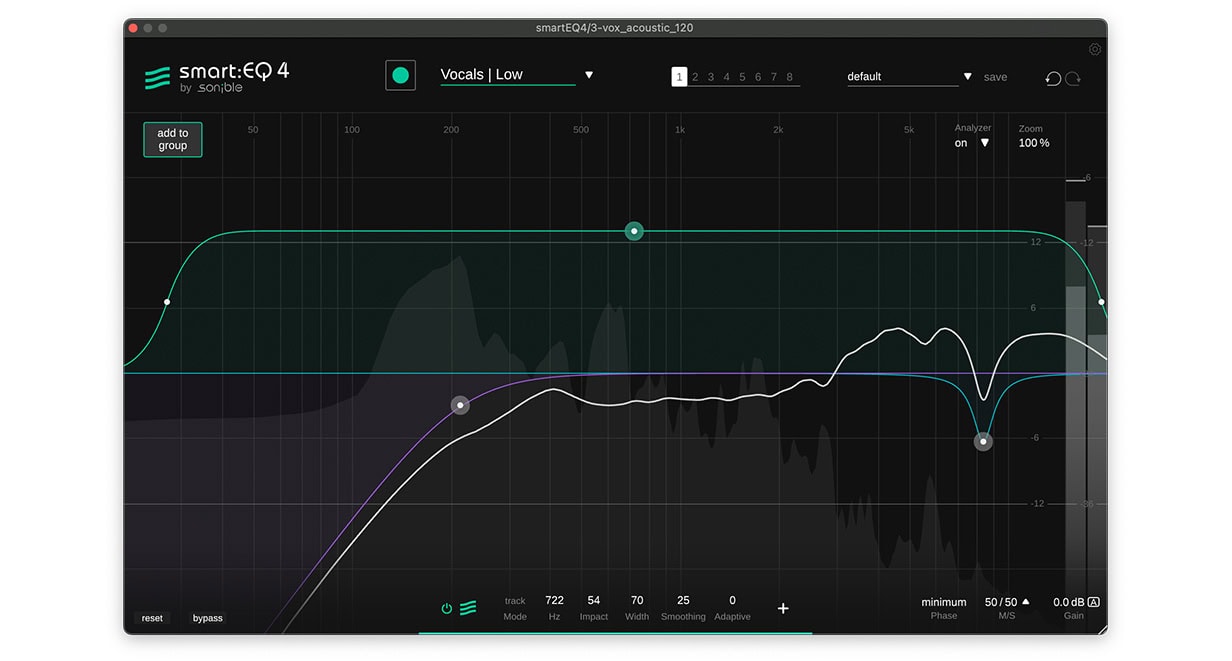
Obwohl die Stimme jetzt isoliert besser klingt, fügt sie sich immer noch nicht gut in den Gesamtmix ein. Einer der Gründe dafür ist, dass sie mit anderen melodischen Elementen des Tracks kollidiert, beispielsweise mit dem Synth-Pad. Wir können die Gruppenfunktion von smart:EQ 4 nutzen, um die Frequenzmaskierung zwischen den beiden Elementen zu beheben.
Lade eine Instanz von smart:EQ 4 auf den Kanal, der mit der Stimme kollidiert, wähle das entsprechende Profil und klicke dann auf ‘Learn‘. Sobald das Plugin das Signal analysiert hat, klicke auf ‘add to group‘. Du wirst nun aufgefordert, die Gruppe zu benennen.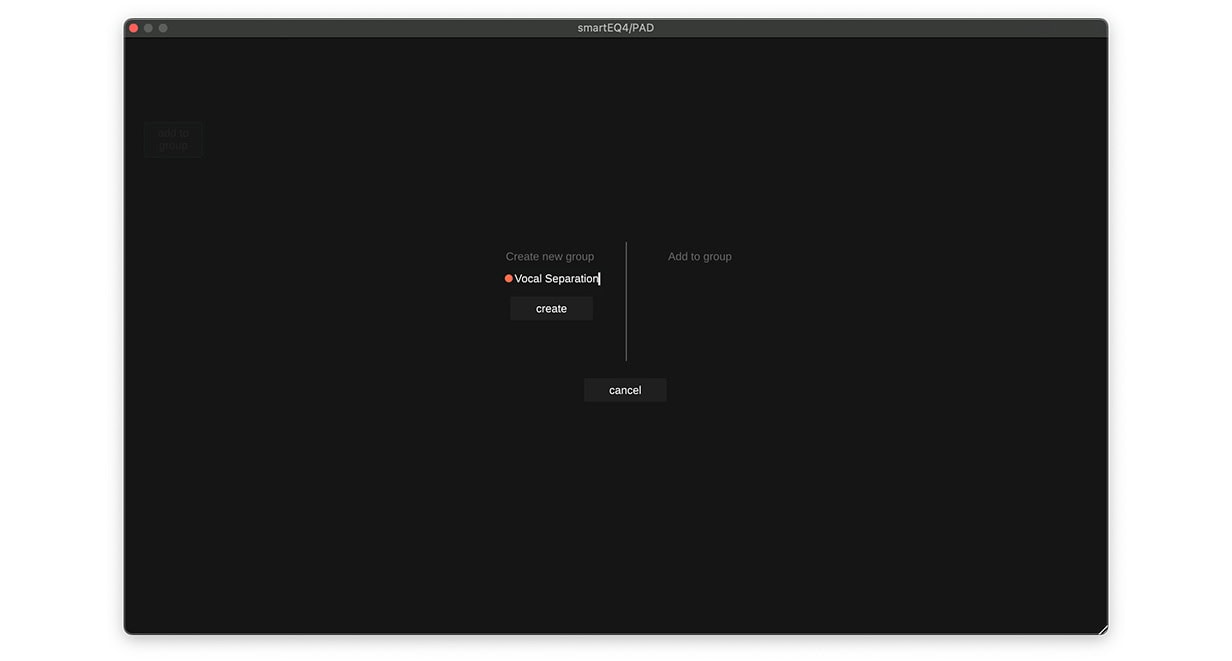
Öffne anschließend die Instanz von smart:EQ 4 für die Stimme, klicke auf ‘add to group‘ und füge sie der Vocal-Separation-Gruppe hinzu. In der Gruppenansicht kannst du sehen, dass sowohl die Stimme als auch das Synthesizer-Pad viele Frequenzinformationen zwischen 200 Hz und 500 Hz enthalten, was dazu führt, dass die beiden Elemente konkurrieren. Indem du den Gesang im Vordergrund und das Pad im Hintergrund platzierst, passt jede Instanz von smart:EQ 4 das EQing so an, dass der Gesang Vorrang vor dem Synthesizer hat.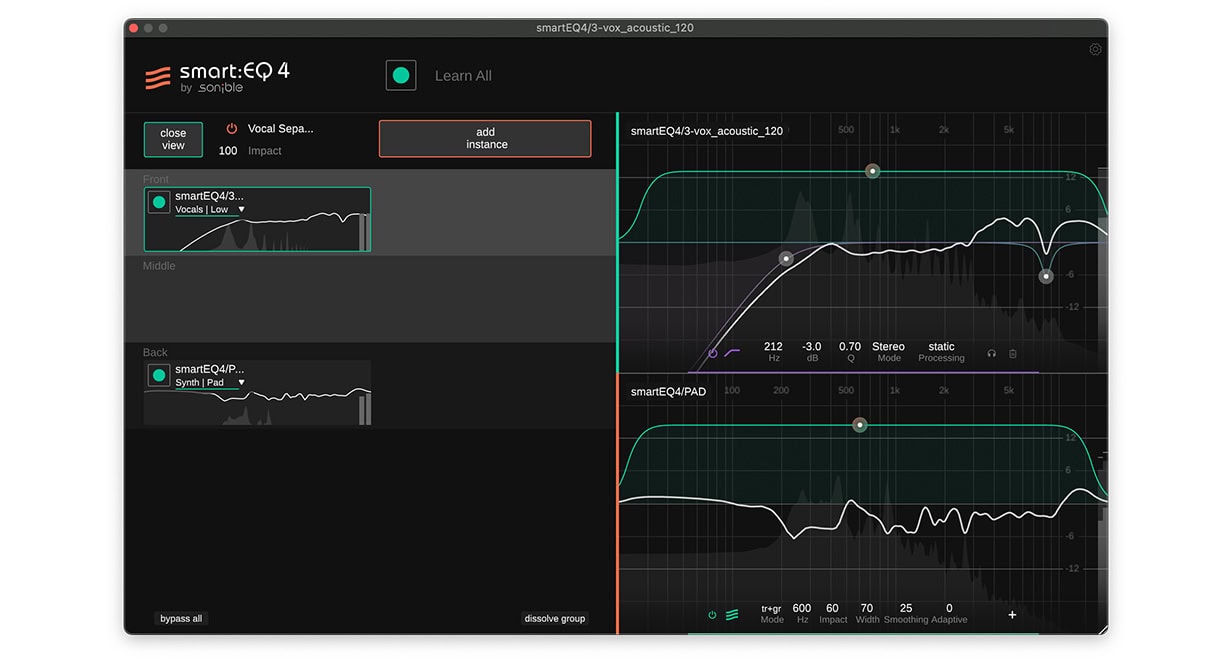
Die Stimme und das Pad kämpfen nun nicht mehr um Platz im unteren Mittenbereich, und die Stimme kann sich im Mix durchsetzen.
Das EQing, so wie wir es im letzten Schritt vorgenommen haben, hat dazu beigetragen, dass sich die Stimme besser in den Mix einfügt. Wir können jedoch noch einen Schritt weiter gehen, indem wir etwas Hall anwenden und der Stimme so mehr Räumlichkeit geben. Wir laden den Reverb auf einen Return-Channel, da in diesem Fall das trockene Gesangssignal bestehen bleibt und wir auch andere Elemente an den Reverb senden können. So entsteht der Eindruck, dass die Elemente der gesamten Mischung in einem bestimmten Raum stattfinden, was wiederum dazu führt, dass wir die Mischung als Ganzes wahrnehmen – nicht mehr als für sich stehende Sektionen.
Lade als erstes einen Reverb auf einen Return-Channel. In unserem Fall verwenden wir smart:reverb (Hinweis: smart:reverb wurde mittlerweile durch smart:reverb 2 ausgetauscht). Da wir den Reverb auf einem Return-Channel nutzen, können wir Dry auf 0 und Wet auf 100 stellen. Der Track hat ein mittleres Tempo mit einem Half-Time Drum-Pattern, so dass wir eine mittlere bis lange Reverb-Zeit von etwa zwei Sekunden verwenden können. Wir haben auch etwas Pre-Delay hinzugefügt, um den Reverb ein bisschen vom trockenen Signal zu trennen.
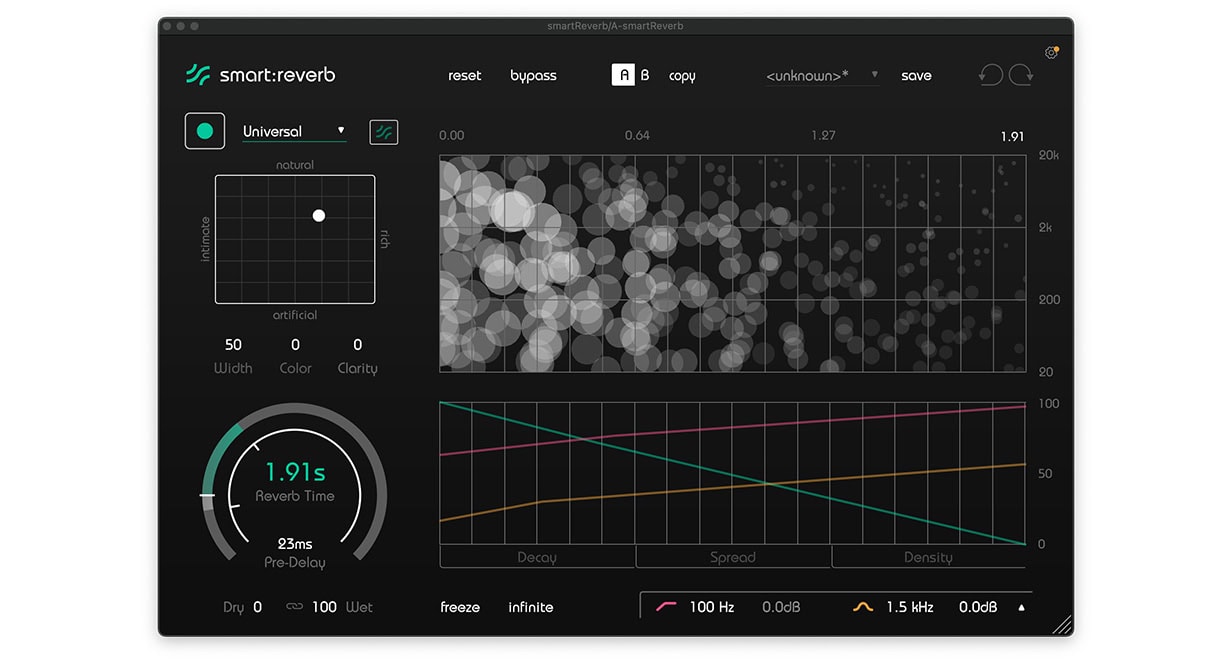
Anschließend schicken wir den Gesang und einige melodische Elemente an den Return-Channel. Es gibt keine richtige beziehungsweise allgemein gültige Einstellung für den Send-Wert jedes Elements. Achte darauf, was du hörst, während du den Return-Kanal solo schaltest und die Regler anpasst, bis du das Gefühl hast, dass die Balance stimmt. Du kannst jetzt das Reverb Level, Reverb Time, Pre Delay und andere Parameter einstellen, bis du mit der Gesamtmischung des Reverbs zufrieden bist.
Du kannst jetzt das Reverb Level, Reverb Time, Pre Delay und andere Parameter einstellen, bis du mit der Gesamtmischung des Reverbs zufrieden bist.
Im Kontext des ganzen Tracks kannst du nun hören, wie sich diese Abmischungstechniken nicht nur auf die Stimme selbst, sondern auf den gesamten Mix ausgewirkt haben.