Bei richtig guten und beliebten Podcasts spielt nicht nur der Inhalt eine immense Rolle, sondern auch der Ton. In diesem Artikel zeigen wir dir, wie du mit smart:EQ 3 und smart:comp drei gängige Audioprobleme in Podcasts beheben kannst – auf schnelle und sehr effektive Weise.
Hinweis: Wir haben smart:comp durch smart:comp 2 ersetzt! Der spektro-dynamische Kompressor enthält nun auch Optionen für die Klangbearbeitung, eine ganze Reihe neuer Profile (Einzeltracks, Busse und Mixes), eine Frei-From Transferfunktion mit Templates für die Kompression, Mid/Side Verarbeitung und vieles mehr.Der folgende Artikel enthält Beispiele, die mit smart:comp erstellt wurden. Die Verarbeitung von smart:comp 2 ist aber in den grundlegenden Funktionsweisen dieselbe wie in smart:comp.
Podcasts sind beliebter denn je: Nicht nur bei Zuhörern sondern auch bei Machern. Für Letztere ist es nicht immer einfach, die Audioqualität zu erreichen, die für einen angenehmen und kurzweiligen Hörgenuss nötig ist: die Bedingungen für Aufnahmen sind nicht immer optimal und oft werden Gäste via Anruf oder Videokonferenz zugeschaltet, was eine große Herausforderung für einen homogenen Klang darstellen kann. Durch die intelligenten Plug-ins smart:EQ 3 und smart:comp kannst du im Handumdrehen dein Audiomaterial klanglich in Form bringen.
Damit du folgende Audiobeispiele in voller Qualität hören kannst, empfehlen wir dir Monitore oder hochwertige Kopfhörer zu verwenden.
Wir zeigen dir, wie schnell du von so einem Podcast …
… zu einem dynamisch und angenehm klingenden Podcast kommst
Von klassischen Podcast-Stimmen erwartet man einen vollen und abgestimmten Klang. Aufgrund von suboptimalen Mikrofonpositionen oder Gästen, die über Online-Kommunikationstools am Gespräch teilnehmen, kann dieser Erwartung oft nicht entsprochen werden. Die intelligente Verarbeitung von smart:EQ 3 sorgt im dynamischen Modus für spektrale Balance, auch wenn es sich um verschiedene Sprecher handelt.
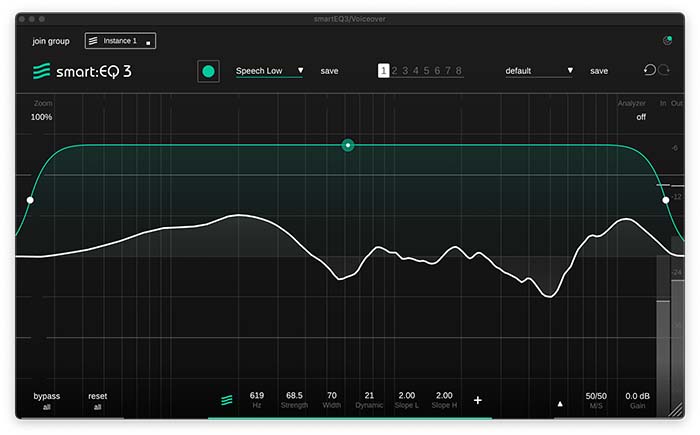
Platziere als erstes eine Instanz von smart:EQ 3 auf der Spur mit den Sprachaufnahmen. Wähle danach ein passendes Profil aus – wir empfehlen „Speech High“ oder „Speech Low“. Starte anschließend das Audio Playback und klicke auf den Aufnahmeknopf. Nachdem smart:EQ 3 einen smart:filter berechnet hat, kannst du die Intensität der Bearbeitung mit der grünen Gewichtungskurve nach Belieben verändern. Aktiviere zum Schluss die dynamische Anpassung indem du den Dynamic Parameter im Filter Widget (Rechtsklick auf den Thumb der Gewichtungskurve) oder in der Parameterbox hochdrehst.
Wenn in Gesprächssituationen mit mehreren Teilnehmern die Lautstärke der Stimmen stark variiert, leidet darunter häufig die Sprachverständlichkeit. Mit smart:comp kannst du durch spektrale Kompression in wenigen Sekunden eine angenehme Balance zwischen den Sprechern herstellen. Die unterschiedlichen Lautstärken werden ausgeglichen und der Klang wird ausgewogener.
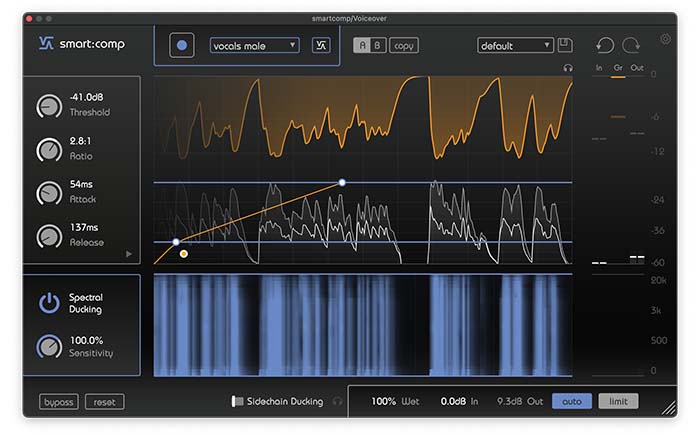
Platziere zuerst smart:comp auf der Spur mit der Sprachaufnahme. Wähle dann ein passendes Profil und starte den Lernvorgang. Wenn notwendig, kannst du zum Abschluss den Output Gain noch erhöhen, um die Stimme auf ein passendes Level zu bringen. Achte dabei darauf, dass der Ausgangspegel immer etwas unter 0 dB liegt, auch wenn smart:comp bei aktiviertem „Limit“ Parameter dank Soft-Clipping dafür sorgt, dass digitales Clipping bei (zu) hohen Ausgangspegeln vermieden wird.
Um im Intro für Aufmerksamkeit zu sorgen oder einen Podcast stellenweise dynamischer zu gestalten, ist musikalische Begleitung ein bewährtes Mittel. Doch gerade zu Beginn eines Podcasts ist es häufig so, dass die Intro-Musik zu laut ist und Gesprochenes deutlich an Verständlichkeit verliert. Mit dem frequenz-selektiven Ducking von smart:comp kannst du für die Stimme Raum schaffen – so bleibt sie klar und deutlich im Rampenlicht ohne dass die Musik ihre Wirkung verliert.
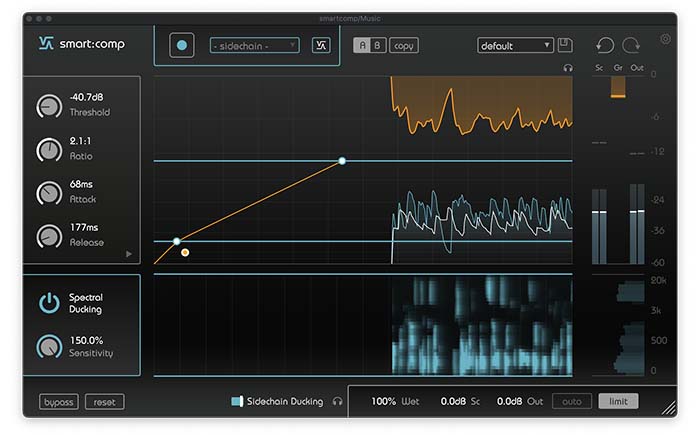
Lade eine Instanz von smart:comp auf die Musikspur und wechsle in den Sidechain Ducking Modus. Wähle die Sprachaufnahmen als Sidechain Input für das Plug-in und starte anschließend den Lernvorgang. Je nach Geschmack kannst du das Hervorheben der Stimme mittels Sensitivity-Einstellung und Threshold verstärken oder abschwächen.
Header und Share Bild: https://flic.kr/p/2imTQYc von BZ | Aad Meijer / verwendet CC BY-SA 2.0 / Bearbeitung des Originals