For a podcast to be successful and popular, not only is good content important but sound also plays a crucial role. In this article, we show you how to use smart:EQ 3 and smart:comp to quickly and effectively tackle three common audio issues when producing podcasts.
Note: We replaced smart:comp with smart:comp 2! The spectro-dynamic compressor now sports sound-shaping option, an entire range of new profiles (single tracks, buses, mixes), a free-form transfer function with compression templates, states, mid/side processing, … and much more.
Podcasts are more popular than ever: Not only with listeners but creators too. For the latter, it’s not always easy to get the audio sounding pleasant: recording conditions are often less than ideal and remote guest speakers can cause a whole lot of acoustic problems. By using the intelligent plug-ins smart:EQ 3 and smart:comp, you’ll be able to whip your podcast audio into shape – with only a few tweaks.
We suggest using high quality headphones or studio monitors when listening to the following audio examples.
We show you how to get from this podcast’s sound …
… to this more engaging and pleasant sound
We expect podcast voices to sound rich and well-balanced. Due to less than ideal microphone positioning or guests who join the conversation via online communication services, it’s not easy to meet this expectation. Using the dynamic mode of smart:EQ 3’s intelligent processing establishes a spectral balance even when there are multiple speakers.
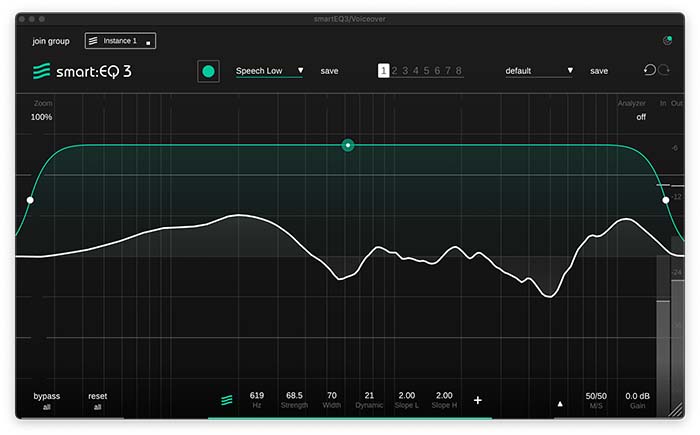
Load an instance of smart:EQ 3 on the tracks that contain all the speakers. Choose a suitable profile – we recommend either “speech high” or “speech low”. Playback the track and click the recording button. After smart:EQ 3 has calculated the smart:filter, you’ll be able to adjust the intensity of the processing to your liking. Then, activate the dynamic mode by increasing the dynamic value in either the parameter box or in the widget (reveal widget by right-clicking the filter thumb).
Intelligibility is decreased when several people with varying voice levels are participating in a conversation. By using smart:comp’s spectral compression you’ll establish spectral balance in no time. Th different levels will be adjusted and the sound immediately becomes more pleasant and consistent.
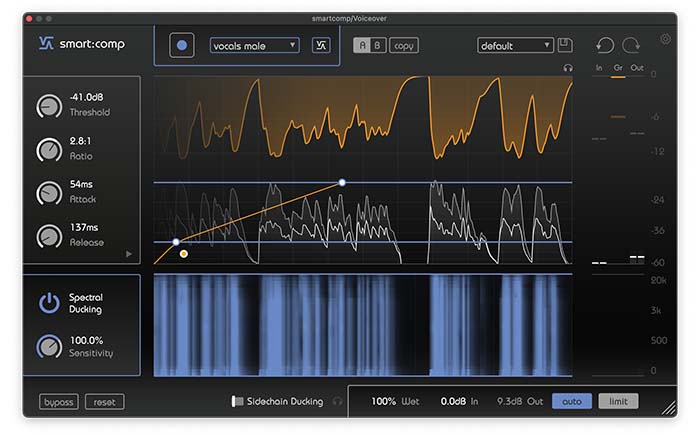
Place smart:comp on the recording of the voices. Choose a profile that matches and initiate learning. If necessary, you can increase the output gain to bring the voices up to the desired level. It’s highly recommended that the output level always stays below 0dB, although smart:comp applies soft-clipping to avoid digital distortion when the “limit” button is enabled.
Music is a great way to get the attention of listeners during the intro as well as making the content more dynamic throughout a podcast. Especially at the beginning of a podcast, it often happens quite often that the music is too loud though and the speaker’s voice is difficult to understand. With the frequency-selective ducking feature of smart:comp, you’ll be able to make room for the voice – precisely where it’s needed. This way, the voice remains clear and distinct in the foreground and the music keeps its effect.
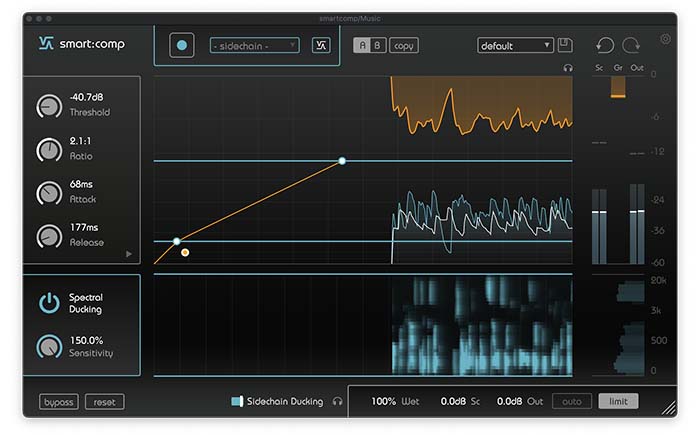
Load an instance of smart:comp on the music track and switch to sidechain mode. Route the voice track as sidechain input for the plug-in and start the learning. You can further accentuate or reduce the ducking effect with the sensitivity setting and the threshold control.
Header and Share image: https://flic.kr/p/2imTQYc by BZ | Aad Meijer / used under CC BY-SA 2.0 / modified from original